
데이터베이스의 종류에는 계층형 데이터베이스, 네트워크형 데이터베이스, 관계형데이터베이스와 비관계형(NoSQL)데이터베이스가 있다. 이 중에서 관계형데이터베이스와 NoSQL데이터베이스를 가장 많이 사용한다.
각각 특징적인 부분이 명확하므로 어떠한 서비스 기능을 구현하느냐에 따라 적절한 데이터베이스를 선택할 필요가 있다.
📌NoSQL의 확장성
NoSQL의 가장 큰 특징은 수평적 확장이 가능하다는 것이다. 단순히 데이터베이스 서버개수를 늘리기만 해도 데이터베이스의 용량을 늘릴수가 있다.
수직적 확장이 컴퓨터의 성능(많은 RAM, 좋은CPU 등)을 올리는거라면 수평적확장은 말그대로 서버만 가져다가 붙이면 쉽게 확장이 가능하기 때문에 대용량 데이터를 저장하기에 수월하다는 장점이있다. 실제로 페이스북이나 트위터같이 많은 데이터를 다루기 다루기 시작하면서 NoSQL이 많이 사용되고 있다고 한다.
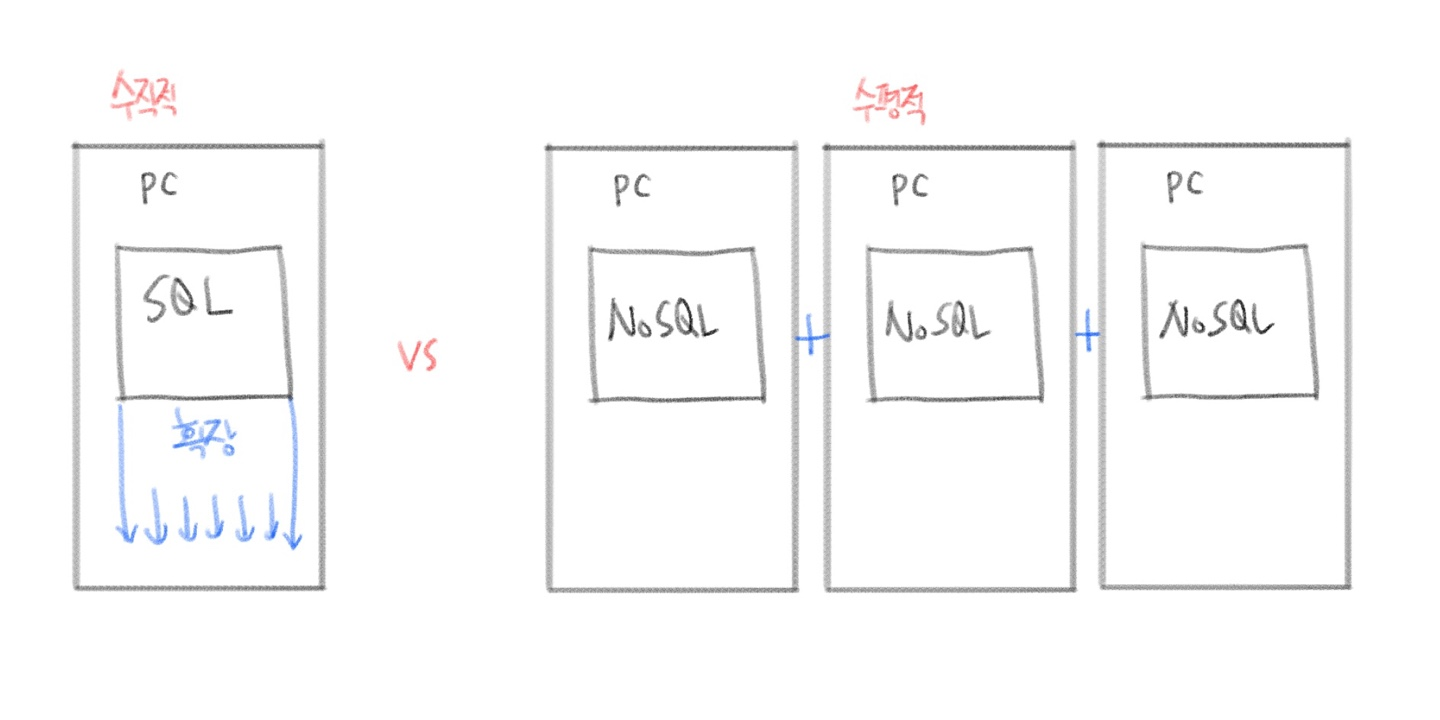
위의 그림처럼 데이터가 대용량으로 늘어나도 수평적으로 확장할 수 있다. 이렇게 수평적으로 확장하는 방식을 샤딩(sharding)이라고도 부르는데, 추후에 샤딩으로 확장하는 방식에 대해서도 알아보면 좋을 것 같다.
📌데이터 저장방식
NoSQL은 SQL처럼 정형화된 쿼리문을 사용하지 않는다. 예를 들면 SQL같은 경우 MySQL이든 Oracle이든 관계형 테이블의 형태에 따라 정형화된 쿼리문법이 존재하는데 반해, NoSQL은 도큐먼트, 그래프, 키-값 등 다양한 형태로 저장할 수 있기 때문에 조금더 유연하게 저장할 수 있다.
도큐먼트(Document)
여러가지 XML, JSON등의 데이터 형태를 사용할 수 있는데 JSON을 예로들면 아래처럼 '문서' 형태로 저장한다.
JSON방식의 특징처럼, 하위에 계속해서 JSON형태의 '문서'를 추가할 수 있다.
{
"_id" : "1",
"name" : "김민지",
"phones" : [ "010-1234-5678", "02-8765-4321" ],
"title" : "아이돌",
"team" : { "name" : "뉴진스", "code" : "s1234" }, "schedules" : [
{ "time" : "20230311130000", "loc" : "강남", "work" : "노래연습" },
{ "time" : "20230411150000", "loc" : "판교", "work" : "춤연습" },
{ "time" : "20230511100000", "loc" : "강북", "work" : "콘서트", "done": true },
{ "time" : "20230611170000", "loc" : "마포", "work" : "행사", "done" :true }
]
}또한 현재는 "_id", "name", "phones", "title", "team"이 있는데, 원한다면 쉽게 "데뷔년도"와같이 데이터를 추가해서 유연하게 넣을 수 도 있다.(관계형 데이터베이스의 테이블과 달리 데이터 형식이 정해져 있지 않음)
대표적으로 MongoDB가 있다.
키-값(Key-Value)
해시테이블 구조처럼 key-value쌍으로 데이터를 저장하고 조회한다. 당연히 key값은 고유값이 되어야한다.
value값에는 어떤 데이터 타입도 가능하기 때문에 데이터를 저장할 때에는 타입에 잘 주의해서 저장해주면 좋을 것이다.
대표적으로 Redis가 있다.
만약 데이터간의 관계가 확실하고 잘 정형화 되어있다면 JOIN문같은 쿼리를 많이 사용하기 때문에 관계형DB가 어울릴 것이고, 그럼에도 대용량 데이터와 수평적 확장이 필요한 구조라면 NoSQL을 고려해야 한다.
SQL vs NoSQL
| 관계형 데이터베이스 | NoSQL 데이터베이스 | |
| 데이터 저장 | 2차원 테이블 | 도큐먼트, 키-값, 그래프등 다양한 형태 |
| 데이터 중복 | 중복 없음 | 중복 가능 -> 데이터 갱신할 때 처리비용 발생 |
| 스키마 | 스키마가 있어 데이터 무결성 보장 | 스키마가 없고 유연한 데이터 처리 가능 |
| 데이터 확장 | 수직적 확장(서버 자체 성능 증가) | 수평적 확장(분산형으로 서버 추가) |
| DBMS | MySQL, Oracle, PostgreSQL | MongoDB |
※무결성 : 데이터베이스 데이터가 실제 데이터과 일치하는지에 대한 정확성, 그리고 데이터의 일관성
관계형 데이터베이스의 무결성을 보장하기 위해서는 여러가지 조건에 맞게(제약 조건) 관계형 데이터베이스가 설계되어야 한다.
1. 개체 무결성
- 모든 테이블은 기본키를 가져야한다.(Null이 될 수 없고, 중복 되지 않는 고유한 값)
2. 도메인 무결성
- 도메인은 테이블이 가질 수 있는 값의 집합으로, 도메인안의 값만 테이블 속성값이 될 수 있다.
ex) 학생도메인을 '이름', '학번', '나이' 로 정의했는데, 실제 테이블 속성에 '성별'이라는 속성은 들어갈 수 없음. 즉, 데이터를 넣을 때 NoSQL처럼 갑자기 '성별'속성이 넣고싶다고 넣을 수 있는게 아니다.
3. 참조 무결성
- 외래키 값은 참조하는 테이블의 기본키값과 동일하거나 Null이어야한다.
ex) 참조하는테이블의 기본키값 5가 없는데, 다른테이블의 외래키에서 5를 사용할 수는 없다. 즉, 참조테이블의 5라는 기본키가 삭제된다면, 참조하는 외래키값도 사라지거나 Null처리가 되어야 한다.
참고자료