
1. 일단 개선을 하긴 했는데..
이전에 프로젝트 구조개선을 시도해보았다. 완성된 아키텍처는 아래와 같다.
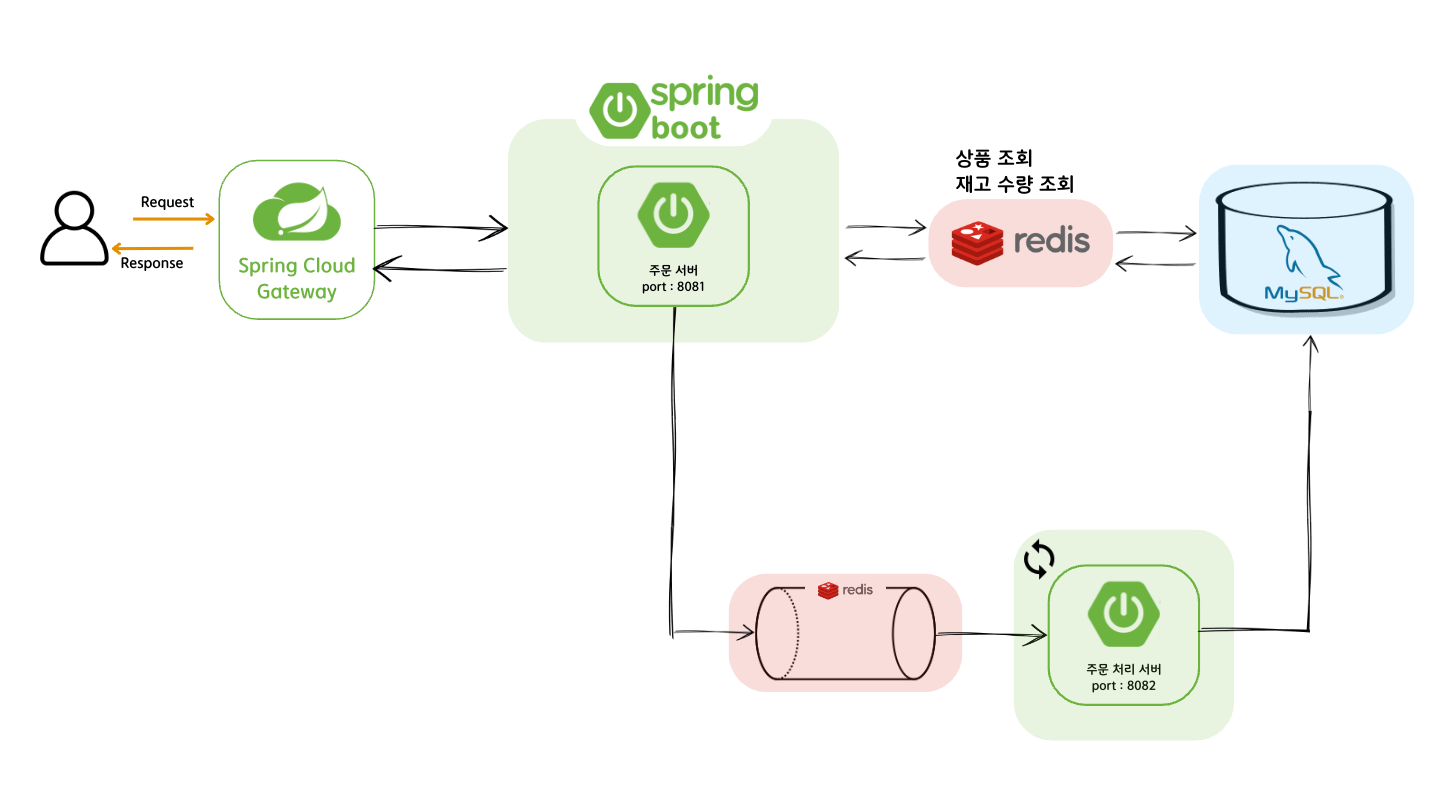
주문 요청에 대한 요청 처리율도 향상되었고, 재고수량의 동시성 문제도 발생하지 않았다.
하지만 위의 개선된 구조는 내가 알고있는 지식 선에서 가능한 빠르게 구조를 잡아본 형태이고, 더 좋은 선택지가 있을 수 있기 때문에 어떠한 선택지가 있었는지 고민해보고, 새로 알게된 @Scheduling에 대해서도 학습해보면 좋을 것 같다.
2. Redis외에 다른 선택지?
1) 로컬 캐시
우선 개선 구조에서 가장 중요하게 생각한 포인트는, 트래픽이 집중될것으로 예상되는 주문 서버의 주문 처리 로직을 MySQL 데이터베이스 I/O를 이용하지 않고 구현하는 것이었다.
그러기 위해서는 캐시 저장소를 활용하면 좋겠다고 생각했고, 시간이 오래걸리는 MySQL I/O의 작업을 비동기적으로 다른 서버에 위임하여 주문 처리 로직을 수행하였다.
결과적으로 위의 그림을 보면 Redis는 총 3가지 일을 수행하고 있다.
1. 상품 조회(유효성 검사)
2. 재고 수량 조회 및 감소
3. 상품 주문 요청을 Queue구조에 발급(오래걸리는 DB I/O 작업을 위임)
여기서 현재 주문 서버는 단일 서버이기 때문에 상품 조회와 같이 단순 조회의 기능만을 수행한다면 redis보다는 로컬 캐시를 활용해도 좋을 것 같다고 생각한다.(로컬 캐시가 redis보다는 조금 더 조회 성능이 좋기 때문..!)
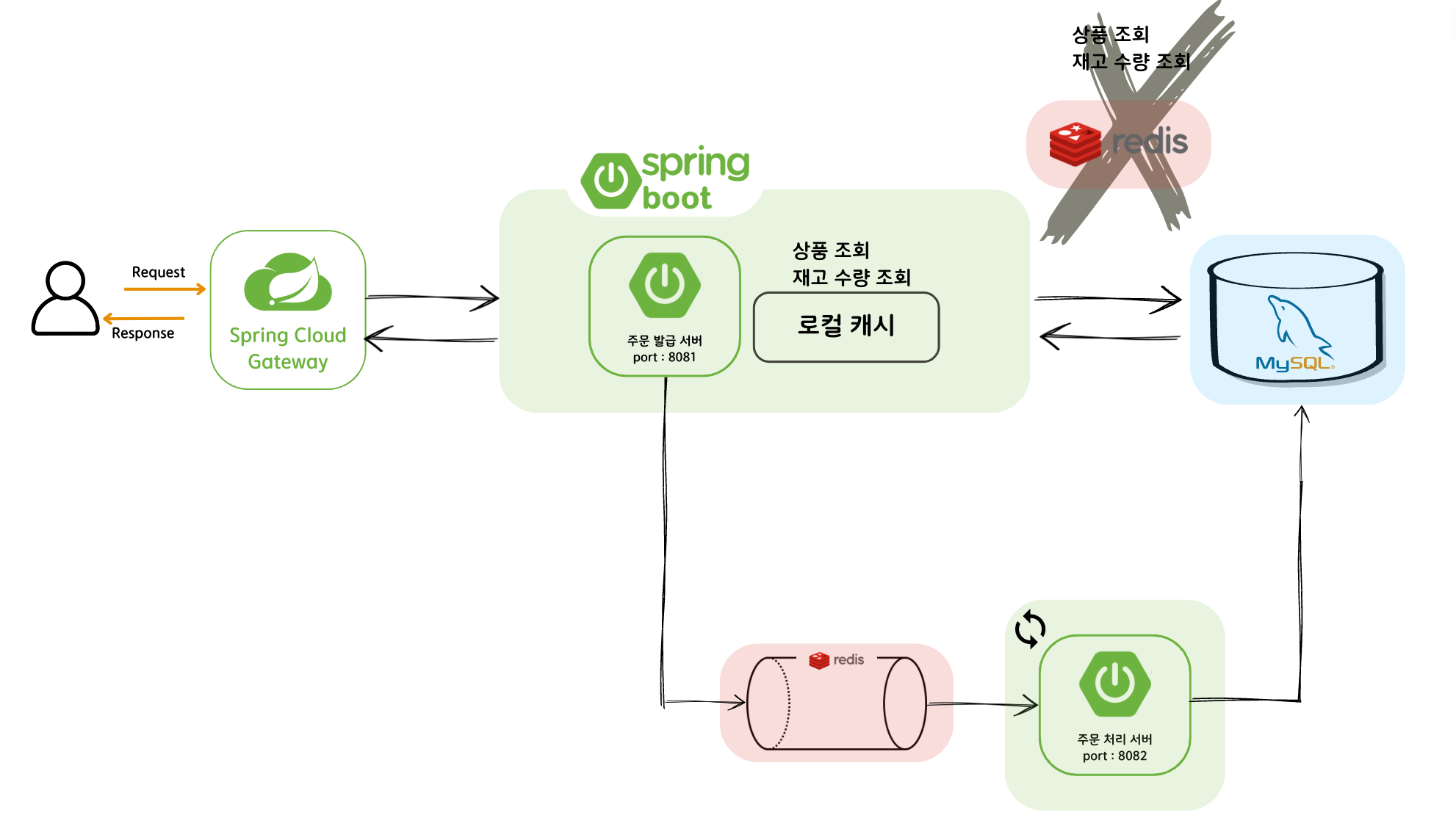
재고 수량의 경우에는 유효성 검증 후에, 주문한 수량만큼 감소시키는 로직이 필요한데 이때 redis의 DECR연산을 활용해서 빠르게 처리할 수 있었다.
2) 메세지 브로커
오래걸리는 작업을 비동기적으로 다른 서버에 위임하기 위에 redis의 List자료구조를 통해 Queue 형식으로 데이터를 삽입하도록 구현하였다.
시간복잡도 측면에서 RPUSH, LPOP연산 모두 O(1)의 시간복잡도로 작업할 수 있었고, 접근성과 구현이 단순했기 때문에 빠르게 적용시켜 보았다.(redis 학습을 목표로 선택한 이유도 있음..!)
단점으로는 redis자체가 인메모리 데이터 저장소 이기 때문에 redis 서버가 다운됐을 때 큐의 데이터가 삭제되어 복구할 수 없다.(redis에서 데이터를 영구적으로 저장하는 방법이 있지만 비용이 소모됨)
그 외에 대안으로는 아래와 같은 기술들이 있다.
1. redis streams : redis의 List자료구조와 다르게 다수의 소비자가 큐 데이터를 처리하도록 기능을 제공한다.(또한 메모리를 더 사용해서 대규모 데이터 처리에도 유리하다고함)
2. Rebbit MQ : (간단 학습중..)
3. kafaka : 생성자/소비자를 유연하게 관리하고 빠른 성능과 장애발생시 데이터 복구 및 재처리가 유리하다.
3. 캐싱 전략?
상품정보와 재고수량 정보를 캐싱할 때에는 Look-Aside 전략을 사용하였다.
Look-Aside 전략이란? : redis에서 key값을 통해 데이터를 조회하고, 만약 없다면 MySQL과 같은 데이터베이스에서 데이터를 조회하여 redis에 적재시키는 방법.
읽기에 자주 사용되는 전략이고, 주의점이라고 한다면 특정 시간에대 구매할 수 있는 수많은 상품들이 오픈된다면 상품 정보가 redis에 존재하지 않아서 순간적으로 MySQL 데이터베이스에 부하가 가해질 수 있다는 점이다.
이를 위해서 상품 오픈 시간 전에 미리 redis 캐시에 데이터를 적재시켜서 순간적으로 MySQL데이터에 부하가 가하지 않도록 캐시 워밍(Cache Warming) 전략을 사용할 수 있다.
4. 스프링 스케쥴링
현재 주문이 발생하면 빠르게 redis의 큐 자료구조에 주문 요청 데이터를 적재시킨다.
이를 처리해줄 별도의 서버를 구축하였는데, 스프링에서 제공해주는 스케쥴링 기능을 이용해서 구현하였다.
@Transactional
@Scheduled(fixedDelay = 1000L)
public void issue() throws JsonProcessingException {
log.info("listening...");
while (existOrderIssue()) {
final OrderIssueRequest target = getIssueTarget();
log.info("발급 시작 target: " + target);
// orders 저장
// 임시 가격 지정
int price = 1000;
OrderEntity order = OrderEntity.create(target, price);
orderRepository.save(order);
// order_history 저장
OrderHistoryEntity orderHistory = OrderHistoryEntity.create(order);
orderHistoryRepository.save(orderHistory);
// 상품 재고 감소
StockEntity stock = stockRepository.findByProductId(target.productId())
.orElseThrow(() -> new GlobalException(HttpStatus.NOT_FOUND, "[ERROR] 상품 재고 찾을 수 없음."));
stock.substract();
stockRepository.save(stock);
log.info("발급 완료 target: " + target);
removeIssuedTarget();
}
}
private boolean existOrderIssue() {
String issueRequestKey = "issue.request";
return redisRepository.lSize(issueRequestKey) > 0;
}
private OrderIssueRequest getIssueTarget() throws JsonProcessingException {
String issueRequestKey = "issue.request";
return objectMapper.readValue(redisRepository.lIndex(issueRequestKey, 0), OrderIssueRequest.class);
}
private void removeIssuedTarget() {
String issueRequestKey = "issue.request";
redisRepository.lPop(issueRequestKey);
}
@Scheduled : 해당 어노테이션이 붙은 메서드를 주기적으로 동작시켜 준다.(@Scheduled 메서드는 반환값이 void이고 파라미터가 존재해선 안됨)
여러가지 속성이 존재하는데 filxedDelay라는 속성을 사용해서, 해당 메서드의 작업이 끝난 후 1초마다 재작업 시켜주는 기능을 사용하였다.
로직으로는 Queue에 데이터가 존재한다면 MySQL 데이터베이스에 저장하고, Queue에서 pop하도록 구현하였다.
@Scheduled는 어떻게 동작하는 것일까?
기본적인 동작방식은 내부적으로 스레드1개를 가지는 스레드풀을 생성하여, 속성값에 맞게 주기적으로 작업을 수행시켜준다.
원한다면 쓰레드 풀을 커스텀하여 멀티 스레드 방식으로도 처리할 수 있다고 한다.
'프로젝트 > 예약상품' 카테고리의 다른 글
| [프로젝트 그 이후...] 선착순 주문 요청 프로젝트 개선하기 (0) | 2024.07.13 |
|---|---|
| [회고] 예약 상품 프로젝트 (0) | 2024.03.04 |
| [프로젝트] 회복탄력성(CircuitBreaker와 Retry) (0) | 2024.03.02 |
| [프로젝트] 상품 오픈시간에 같은 사용자의 여러 요청을 대비하자 (0) | 2024.02.26 |
| [프로젝트] redis로 동시성 문제를 접근해보자 (0) | 2024.02.26 |
1. 일단 개선을 하긴 했는데..
이전에 프로젝트 구조개선을 시도해보았다. 완성된 아키텍처는 아래와 같다.
주문 요청에 대한 요청 처리율도 향상되었고, 재고수량의 동시성 문제도 발생하지 않았다.
하지만 위의 개선된 구조는 내가 알고있는 지식 선에서 가능한 빠르게 구조를 잡아본 형태이고, 더 좋은 선택지가 있을 수 있기 때문에 어떠한 선택지가 있었는지 고민해보고, 새로 알게된 @Scheduling에 대해서도 학습해보면 좋을 것 같다.
2. Redis외에 다른 선택지?
1) 로컬 캐시
우선 개선 구조에서 가장 중요하게 생각한 포인트는, 트래픽이 집중될것으로 예상되는 주문 서버의 주문 처리 로직을 MySQL 데이터베이스 I/O를 이용하지 않고 구현하는 것이었다.
그러기 위해서는 캐시 저장소를 활용하면 좋겠다고 생각했고, 시간이 오래걸리는 MySQL I/O의 작업을 비동기적으로 다른 서버에 위임하여 주문 처리 로직을 수행하였다.
결과적으로 위의 그림을 보면 Redis는 총 3가지 일을 수행하고 있다.
1. 상품 조회(유효성 검사)
2. 재고 수량 조회 및 감소
3. 상품 주문 요청을 Queue구조에 발급(오래걸리는 DB I/O 작업을 위임)
여기서 현재 주문 서버는 단일 서버이기 때문에 상품 조회와 같이 단순 조회의 기능만을 수행한다면 redis보다는 로컬 캐시를 활용해도 좋을 것 같다고 생각한다.(로컬 캐시가 redis보다는 조금 더 조회 성능이 좋기 때문..!)
재고 수량의 경우에는 유효성 검증 후에, 주문한 수량만큼 감소시키는 로직이 필요한데 이때 redis의 DECR연산을 활용해서 빠르게 처리할 수 있었다.
2) 메세지 브로커
오래걸리는 작업을 비동기적으로 다른 서버에 위임하기 위에 redis의 List자료구조를 통해 Queue 형식으로 데이터를 삽입하도록 구현하였다.
시간복잡도 측면에서 RPUSH, LPOP연산 모두 O(1)의 시간복잡도로 작업할 수 있었고, 접근성과 구현이 단순했기 때문에 빠르게 적용시켜 보았다.(redis 학습을 목표로 선택한 이유도 있음..!)
단점으로는 redis자체가 인메모리 데이터 저장소 이기 때문에 redis 서버가 다운됐을 때 큐의 데이터가 삭제되어 복구할 수 없다.(redis에서 데이터를 영구적으로 저장하는 방법이 있지만 비용이 소모됨)
그 외에 대안으로는 아래와 같은 기술들이 있다.
1. redis streams : redis의 List자료구조와 다르게 다수의 소비자가 큐 데이터를 처리하도록 기능을 제공한다.(또한 메모리를 더 사용해서 대규모 데이터 처리에도 유리하다고함)
2. Rebbit MQ : (간단 학습중..)
3. kafaka : 생성자/소비자를 유연하게 관리하고 빠른 성능과 장애발생시 데이터 복구 및 재처리가 유리하다.
3. 캐싱 전략?
상품정보와 재고수량 정보를 캐싱할 때에는 Look-Aside 전략을 사용하였다.
Look-Aside 전략이란? : redis에서 key값을 통해 데이터를 조회하고, 만약 없다면 MySQL과 같은 데이터베이스에서 데이터를 조회하여 redis에 적재시키는 방법.
읽기에 자주 사용되는 전략이고, 주의점이라고 한다면 특정 시간에대 구매할 수 있는 수많은 상품들이 오픈된다면 상품 정보가 redis에 존재하지 않아서 순간적으로 MySQL 데이터베이스에 부하가 가해질 수 있다는 점이다.
이를 위해서 상품 오픈 시간 전에 미리 redis 캐시에 데이터를 적재시켜서 순간적으로 MySQL데이터에 부하가 가하지 않도록 캐시 워밍(Cache Warming) 전략을 사용할 수 있다.
4. 스프링 스케쥴링
현재 주문이 발생하면 빠르게 redis의 큐 자료구조에 주문 요청 데이터를 적재시킨다.
이를 처리해줄 별도의 서버를 구축하였는데, 스프링에서 제공해주는 스케쥴링 기능을 이용해서 구현하였다.
@Transactional
@Scheduled(fixedDelay = 1000L)
public void issue() throws JsonProcessingException {
log.info("listening...");
while (existOrderIssue()) {
final OrderIssueRequest target = getIssueTarget();
log.info("발급 시작 target: " + target);
// orders 저장
// 임시 가격 지정
int price = 1000;
OrderEntity order = OrderEntity.create(target, price);
orderRepository.save(order);
// order_history 저장
OrderHistoryEntity orderHistory = OrderHistoryEntity.create(order);
orderHistoryRepository.save(orderHistory);
// 상품 재고 감소
StockEntity stock = stockRepository.findByProductId(target.productId())
.orElseThrow(() -> new GlobalException(HttpStatus.NOT_FOUND, "[ERROR] 상품 재고 찾을 수 없음."));
stock.substract();
stockRepository.save(stock);
log.info("발급 완료 target: " + target);
removeIssuedTarget();
}
}
private boolean existOrderIssue() {
String issueRequestKey = "issue.request";
return redisRepository.lSize(issueRequestKey) > 0;
}
private OrderIssueRequest getIssueTarget() throws JsonProcessingException {
String issueRequestKey = "issue.request";
return objectMapper.readValue(redisRepository.lIndex(issueRequestKey, 0), OrderIssueRequest.class);
}
private void removeIssuedTarget() {
String issueRequestKey = "issue.request";
redisRepository.lPop(issueRequestKey);
}
@Scheduled : 해당 어노테이션이 붙은 메서드를 주기적으로 동작시켜 준다.(@Scheduled 메서드는 반환값이 void이고 파라미터가 존재해선 안됨)
여러가지 속성이 존재하는데 filxedDelay라는 속성을 사용해서, 해당 메서드의 작업이 끝난 후 1초마다 재작업 시켜주는 기능을 사용하였다.
로직으로는 Queue에 데이터가 존재한다면 MySQL 데이터베이스에 저장하고, Queue에서 pop하도록 구현하였다.
@Scheduled는 어떻게 동작하는 것일까?
기본적인 동작방식은 내부적으로 스레드1개를 가지는 스레드풀을 생성하여, 속성값에 맞게 주기적으로 작업을 수행시켜준다.
원한다면 쓰레드 풀을 커스텀하여 멀티 스레드 방식으로도 처리할 수 있다고 한다.
'프로젝트 > 예약상품' 카테고리의 다른 글
| [프로젝트 그 이후...] 선착순 주문 요청 프로젝트 개선하기 (0) | 2024.07.13 |
|---|---|
| [회고] 예약 상품 프로젝트 (0) | 2024.03.04 |
| [프로젝트] 회복탄력성(CircuitBreaker와 Retry) (0) | 2024.03.02 |
| [프로젝트] 상품 오픈시간에 같은 사용자의 여러 요청을 대비하자 (0) | 2024.02.26 |
| [프로젝트] redis로 동시성 문제를 접근해보자 (0) | 2024.02.26 |