
테이블 더미데이터 삽입(약 100만개)
프로젝트에 적용시켜 볼 조회쿼리에 대한 성능을 측정하기로 했다.
성능 측정에 필요한 테이블에 약 100만개 정도의 데이터를 삽입하기로 했다.
프로젝트에서 사용한 테이블 구조는 아래와 같다.
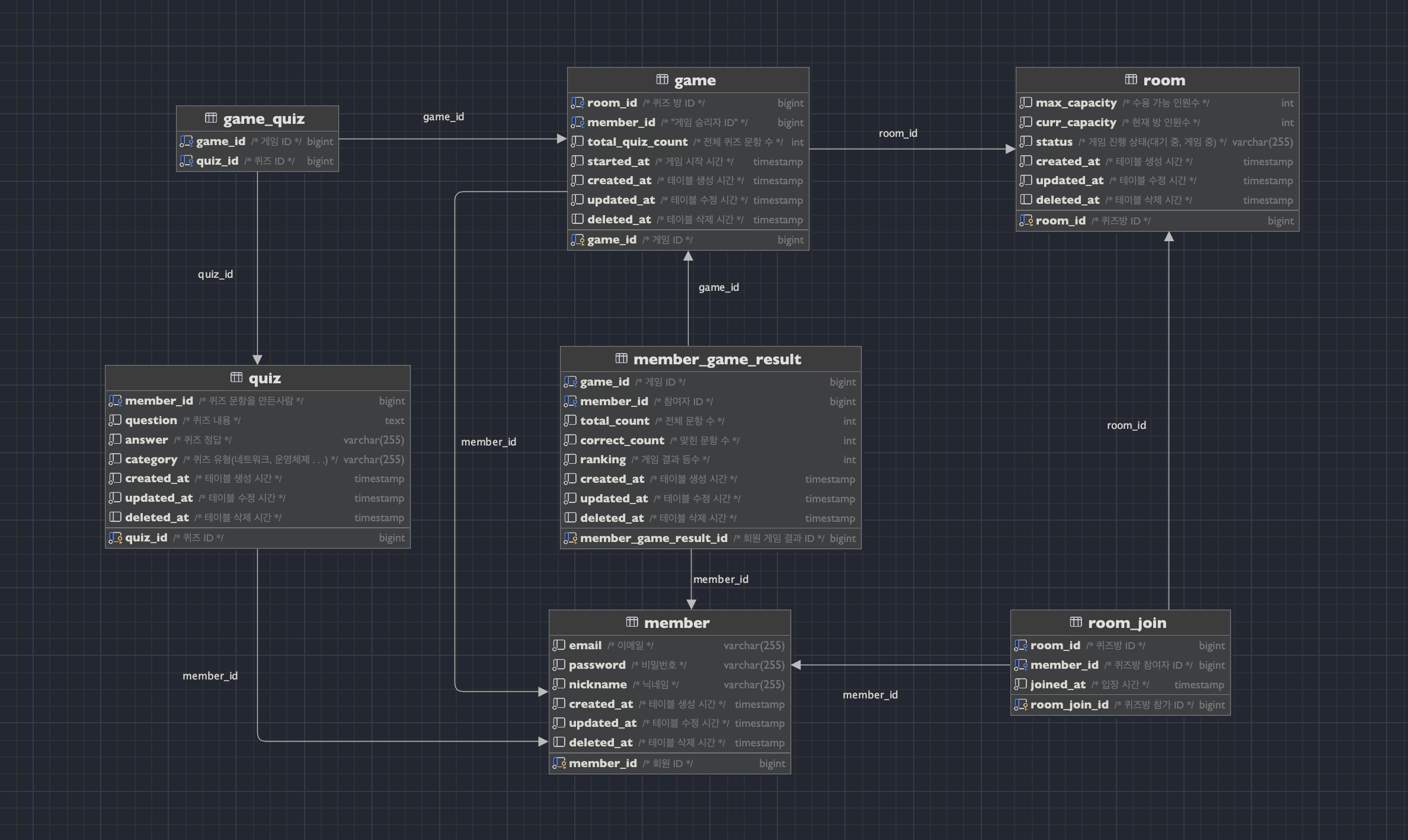
복잡한 조회에 사용되는 테이블은 크게 아래 4개와 같다.
game, member_game_result, game_quiz, quiz
그래서 4개의 테이블에 약 100만개의 데이터를 삽입해주었다.
아래와 같은 코드를 통해 정합성을 맞춰주면서 랜덤 데이터를 최대한 넣어 주었습니다!
퀴즈 테이블(quiz) -> 100만개 생성
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- 더미 데이터 삽입 쿼리
INSERT INTO quiz (member_id, question, answer, category, created_at, updated_at, deleted_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR(1 + RAND() * 3) AS member_id,
CONCAT('문제 ', LPAD(n, 7, '0')) AS question,
CONCAT('정답 ', LPAD(n, 7, '0')) AS answer,
ELT(FLOOR(1 + RAND() * 5), 'NETWORK', 'ALGORITHM', 'OPERATING_SYSTEM', 'DATABASE', 'DESIGN_PATTERN') AS category,
NOW() - INTERVAL (n) MINUTE AS created_at,
NOW() - INTERVAL (n) MINUTE AS updated_at,
NULL AS deleted_at
FROM cte;
게임 테이블(game) -> 100만개 생성
-- 더미 데이터 삽입 쿼리
INSERT INTO game (room_id, member_id, total_quiz_count, started_at, created_at, updated_at, deleted_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR(1 + RAND() * 10) AS room_id,
FLOOR(1 + RAND() * 3) AS member_id,
10 AS total_quiz_count,
NOW() - INTERVAL (n + 1) MINUTE AS started_at,
NOW() - INTERVAL (n) MINUTE AS created_at,
NOW() - INTERVAL (n) MINUTE AS updated_at,
NULL AS deleted_at
FROM cte;
-- 컬럼별 더미 데이터 삽입
-- 1. room_id : 게임방 10개 랜덤으로 삽입
-- 2. member_id : 멤버 3명 랜덤으로 삽입
-- 3. total_quiz_count : 10개
-- 4. started_at : 게임 시작 시간은 created_at(게임 종료 시간) 보다 빨라야 한다
-- 5. created_at, updated_at는 현재 시간 기준 n분 전으로 설정
-- 6. deleted_at는 전부 null로 설정해 삭제된 데이터 없음
게임-퀴즈 테이블(game_quiz) -> 1000만개(게임에서 활용된 퀴즈 개수가 10개라고 가정하였습니다.)
// [임시 테이블 생성]
// 게임_퀴즈 테이블의 경우 정합성을 맞춰야 하는 문제가 있음
// 한 게임 아이디에 해당하는 퀴즈들의 카테고리는 일치해야함
// 따라서 임시 테이블마다 카테고리 하나씩 담당해서 랜덤으로 삽입 후
// id 기본키를 삽입해 시간복잡도 O(1)으로 만들어서 접근하게 함
CREATE TABLE tmp_network (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
CREATE TABLE tmp_algorithm (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
CREATE TABLE tmp_operating_system (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
CREATE TABLE tmp_database (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
CREATE TABLE tmp_design_pattern (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
-- 임시 테이블
INSERT INTO tmp_network (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'NETWORK';
INSERT INTO tmp_algorithm (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'ALGORITHM';
INSERT INTO tmp_operating_system (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'OPERATING_SYSTEM';
INSERT INTO tmp_database (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'DATABASE';
INSERT INTO tmp_design_pattern (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'DESIGN_PATTERN';
------------------------------------------------------------------------------------------
// 테이블 삽입
-- 쿼리 콘솔마다 세션 적용되므로 각각 적용 시켜줘야함
SET SESSION cte_max_recursion_depth = 10000000;
-- 더미 데이터 삽입 쿼리
INSERT INTO game_quiz (game_id, quiz_id)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 10000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR((n - 1) / 10) + 1 AS game_id,
CASE FLOOR((((n - 1) / 10) + 1) % 5 + 1)
WHEN 1 THEN (SELECT quiz_id
FROM tmp_algorithm
WHERE id = (n % 190000) + 1
)
WHEN 2 THEN (SELECT quiz_id
FROM tmp_network
WHERE id = (n % 190000) + 1
)
WHEN 3 THEN (SELECT quiz_id
FROM tmp_database
WHERE id = (n % 190000) + 1
)
WHEN 4 THEN (SELECT quiz_id
FROM tmp_design_pattern
WHERE id = (n % 190000) + 1
)
WHEN 5 THEN (SELECT quiz_id
FROM tmp_operating_system
WHERE id = (n % 190000) + 1
)
ELSE 9999
END AS quiz_id
FROM cte;
멤버-게임-결과 테이블(member_game_result) -> 300만개
-- 더미 데이터 삽입 쿼리
INSERT INTO member_game_result (game_id, member_id, total_count, correct_count, ranking,
created_at, updated_at, deleted_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 3000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR((n - 1) / 3) + 1 AS game_id,
FLOOR((n - 1) % 3) + 1 AS member_id,
10 AS total_count,
(CASE (SELECT member_id
FROM game
WHERE game_id = FLOOR((n - 1) / 3) + 1)
WHEN FLOOR((n - 1) % 3) + 1 THEN 5
ELSE 2
END
) AS correct_count,
(CASE (SELECT member_id
FROM game
WHERE game_id = FLOOR((n - 1) / 3) + 1)
WHEN FLOOR((n - 1) % 3) + 1 THEN 1
ELSE 2
END
) AS ranking,
NOW() - INTERVAL (n) MINUTE AS created_at,
NOW() - INTERVAL (n) MINUTE AS updated_at,
NULL AS deleted_at
FROM cte;
-- 컬럼별 더미 데이터 삽입
-- 1. game_id : 3개의 n 값마다 game_id가 1씩 증가 (1,1,1,2,2,2,3,3,3 ...)
-- 2. member_id : 3의 주기로 1, 2, 3을 반복 (1,2,3,1,2,3 ...)
-- 3. total_count : 10개
-- 4. correct_count : 승리자의 경우 맞춘 개수 5개, 나머지 두 멤버는 2개씩 삽입
-- 5. ranking : 승리자의 경우 랭킹 1위, 나머지 두 멤버는 2위로 삽입
-- 6. created_at, updated_at는 현재 시간 기준 n분 전으로 설정
-- 7. deleted_at는 전부 null로 설정해 삭제된 데이터 없음
생각보다 정합성을 맞춰주면서 많은 랜덤 데이터를 넣어주는 코드를 작성하는 것이 쉽지 않았다.
더 좋은 방법이 있었을 수도 있지만, 우선 생각나는 대로 작성해 보았고, 무사히(?) 생성할 수 있었다.
그럼이제 성능 측정 가보자고~

조회 성능 측정해보기

9번. 특정 플레이어가 카테고리별 승리한 횟수를 조회하는 쿼리를 개선해보기로 했다.
(조회 특징을 가지는 쿼리는 page형태로 LIMIT을 걸어서 가져올 수 있는 부분이었다. 그 중에서 '특정 플레이어의 카테고리별 승리 횟수 조회'는 비즈니스 적으로도 가장 궁금해 할 수 있기 때문에 성능 개선후 플젝에 빠르게 적용시켜보고자 선택하였다)
대체 저 40초 로직은 어떻게 쿼리를 작성했길래 저 모양이야..?
네... 바로 아래와 같습니다
SELECT
mgr.member_id,
q.category,
COUNT(DISTINCT g.game_id) AS win_count_by_category
FROM
quiz AS q
INNER JOIN game_quiz AS gq ON q.quiz_id = gq.quiz_id
INNER JOIN game AS g ON gq.game_id = g.game_id
INNER JOIN member_game_result AS mgr ON g.game_id = mgr.game_id
WHERE
mgr.ranking = 1
AND mgr.member_id = '3'
AND q.deleted_at IS NULL
AND g.deleted_at IS NULL
AND mgr.deleted_at IS NULL
GROUP BY
mgr.member_id,
q.category;
-- [2024-09-10 00:09:51] 40 s 895 ms (execution: 40 s 866 ms, fetching: 29 ms)에서 1부터 5개 행을 불러왔습니다
EXPLAIN : 우선 위의 쿼리에 대해 실행 계획을 살펴보면 아래와 같다.
+--+-----------+-----+----------+------+-------------+-------+-------+-------------------+-------+--------+------------------------------------------+
|id|select_type|table|partitions|type |possible_keys|key |key_len|ref |rows |filtered|Extra |
+--+-----------+-----+----------+------+-------------+-------+-------+-------------------+-------+--------+------------------------------------------+
|1 |SIMPLE |gq |null |ALL |null |null |null |null |9741573|100 |Using temporary; Using filesort |
|1 |SIMPLE |q |null |eq_ref|PRIMARY |PRIMARY|8 |cstar_db.gq.quiz_id|1 |10 |Using where |
|1 |SIMPLE |g |null |eq_ref|PRIMARY |PRIMARY|8 |cstar_db.gq.game_id|1 |10 |Using where |
|1 |SIMPLE |mgr |null |ALL |null |null |null |null |2987614|0.01 |Using where; Using join buffer (hash join)|
+--+-----------+-----+----------+------+-------------+-------+-------+-------------------+-------+--------+------------------------------------------+full table scan이 2개나 존재하고 실제로 rows를 보면 행을 굉장히 많이탐색했다는 것을 알 수 있다.
EXPLAIN ANALYYZE : 조금 더 자세히 알아보면 아래와 같다.
-> Group aggregate: count(distinct game.game_id) (actual time=52382..53275 rows=5 loops=1)
-> Sort: q.category (actual time=52173..52396 rows=3.33e+6 loops=1)
-> Stream results (cost=139e+6 rows=2910) (actual time=46656..50792 rows=3.33e+6 loops=1)
-> Inner hash join (mgr.game_id = gq.game_id) (cost=139e+6 rows=2910) (actual time=46656..50203 rows=3.33e+6 loops=1)
-> Filter: ((mgr.member_id = 3) and (mgr.ranking = 1) and (mgr.deleted_at is null)) (cost=1266 rows=299) (actual time=0.31..1230 rows=332942 loops=1)
-> Table scan on mgr (cost=1266 rows=2.99e+6) (actual time=0.295..1009 rows=3e+6 loops=1)
-> Hash
-> Nested loop inner join (cost=12.8e+6 rows=97416) (actual time=0.562..44434 rows=10e+6 loops=1)
-> Nested loop inner join (cost=11.7e+6 rows=974157) (actual time=0.193..37848 rows=10e+6 loops=1)
-> Table scan on gq (cost=999175 rows=9.74e+6) (actual time=0.121..5100 rows=10e+6 loops=1)
-> Filter: (q.deleted_at is null) (cost=1 rows=0.1) (actual time=0.00298..0.00308 rows=1 loops=10e+6)
-> Single-row index lookup on q using PRIMARY (quiz_id=gq.quiz_id) (cost=1 rows=1) (actual time=0.00283..0.00287 rows=1 loops=10e+6)
-> Filter: (g.deleted_at is null) (cost=1 rows=0.1) (actual time=365e-6..470e-6 rows=1 loops=10e+6)
-> Single-row index lookup on g using PRIMARY (game_id=gq.game_id) (cost=1 rows=1) (actual time=218e-6..253e-6 rows=1 loops=10e+6)
사실 이때부터 분석이 점점 어려워지고 분석하는 방법에 대해 자세히 공부해봐야 겠다는 생각을 하게되었다.
(명령어만 칠줄 아는 바보..) -> SQL 쿼리 튜닝 스터디를 시작하게 된 계기..(링크 걸 예정)

우선 개선시도를 아래와 같은 단계로 해보았다.
1. 비효율적인 쿼리 개선
2. 인덱스등을 활용한 개선
3. 테이블 수정하기
1. 기존에 쿼리에서 혹시 굳이 사용하지 않아도 되는구문이 있는지, 불필요하게 사용된 구문이 있는지 확인하고 제거해주었다.
-- 기존쿼리 : 특정 플레이어가 카테고리 별 승리한 횟수 조회 (약 40초)
SELECT
mgr.member_id,
q.category,
COUNT(DISTINCT g.game_id) AS win_count_by_category
FROM
quiz AS q
INNER JOIN game_quiz AS gq ON q.quiz_id = gq.quiz_id
INNER JOIN game AS g ON gq.game_id = g.game_id
INNER JOIN member_game_result AS mgr ON g.game_id = mgr.game_id
WHERE
mgr.ranking = 1
AND mgr.member_id = '3'
GROUP BY
q.category;
-- 개선 쿼리 :
select category, COUNT(*)
from (select q.category, g.game_id
from game g
join game_quiz gq on g.game_id = gq.game_id
join quiz q on q.quiz_id = gq.quiz_id
where g.member_id = 1
group by q.category, g.game_id) AS bbb
group by bbb.category;game 테이블의 member_id는 승리자의 아이디이고, 해당 값은 주어질 이미 주어질 예정이기 때문에 mgr.ranking = 1을 가져올 필요가 없다. 그래서 조인 대상에서 삭제해 주었다.
성능 적인 부분에서는 큰 변화 없없음
2. 인덱스를 적용해보자.
game_quiz라는 맵핑 형태의 테이블을 통해 game과 quiz를 조회 하고있다.실제로 인덱스가 적용되지 않은 채로 join연산을 하는것을 앞의 실행계획에서 확인했었다.
인덱스를 걸어주고난 결과는 아래와 같다.
game_quiz의 game_id필드에 인덱스를 설정한 경우 -> 약 21초
// 게임 아이디에 하나 인덱스
- 카디널리티가 퀴즈 아이디 하나 인덱스 걸었을 때보다 높다
- 게임 아이디는 10개만 중복, 퀴즈 아이디는 중복이 훨씬 많다.
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|Table |Non_unique|Key_name |Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|Visible|Expression|
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|game_quiz|1 |idx_game_id|1 |game_id |A |998215 |null |null | |BTREE | | |YES |null |
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
game_quiz의 quiz_id필드에 인덱스를 설정한 경우 -> 약 1분 18초
// 퀴즈 아이디에 하나 인덱스
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|Table |Non_unique|Key_name |Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|Visible|Expression|
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|game_quiz|1 |idx_quiz_id|1 |quiz_id |A |190879 |null |null | |BTREE | | |YES |null |
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
game_id는 약 20초로 성능향상이 있었고, quiz_id는 약 1분 18초로 성능이 느려졌다.
인덱스를 걸었을 때 카디널리티가 game_id에 걸었을 때가 더 높기 때문이라고 생각한다.
(quiz는 카테고리 별로 약 20만개씩 5덩어리가 존재하고, 그 중에서 랜덤으로 game_id에 10개씩 매칭되는데, 그래서 카디널리티가 더 낮다고 생각됨)
마지막으로 멀티컬럼 인덱스를 적용해보았는데, game_id의 카디널리티가 더 높으므로 (game_id, quiz_id)로 걸었을 때 더 좋은 성능이 나왔다. -> 약 12초
[실행계획 확인]
// 멀티 컬럼 인덱스 -> game id 부터
CREATE INDEX idx_game_id_quiz_id ON game_quiz (game_id, quiz_id);
+---------+----------+-------------------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|Table |Non_unique|Key_name |Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|Visible|Expression|
+---------+----------+-------------------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|game_quiz|1 |idx_game_id_quiz_id|1 |game_id |A |983100 |null |null | |BTREE | | |YES |null |
|game_quiz|1 |idx_game_id_quiz_id|2 |quiz_id |A |9724594 |null |null | |BTREE | | |YES |null |
+---------+----------+-------------------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
// EXPLAIN
+--+-----------+-----+----------+------+-------------------+-------------------+-------+--------------------+-------+--------+--------------------------------------------+
|id|select_type|table|partitions|type |possible_keys |key |key_len|ref |rows |filtered|Extra |
+--+-----------+-----+----------+------+-------------------+-------------------+-------+--------------------+-------+--------+--------------------------------------------+
|1 |SIMPLE |mgr |null |ALL |null |null |null |null |2987614|0.1 |Using where; Using temporary; Using filesort|
|1 |SIMPLE |g |null |eq_ref|PRIMARY |PRIMARY |8 |cstar_db.mgr.game_id|1 |10 |Using where |
|1 |SIMPLE |gq |null |ref |idx_game_id_quiz_id|idx_game_id_quiz_id|8 |cstar_db.mgr.game_id|9 |100 |Using index |
|1 |SIMPLE |q |null |eq_ref|PRIMARY |PRIMARY |8 |cstar_db.gq.quiz_id |1 |10 |Using where |
+--+-----------+-----+----------+------+-------------------+-------------------+-------+--------------------+-------+--------+--------------------------------------------+
// EXPLAIN ANALYZE
-> Group aggregate: count(distinct game.game_id) (actual time=14600..15507 rows=5 loops=1)
-> Sort: q.category (actual time=14384..14620 rows=3.34e+6 loops=1)
-> Stream results (cost=315610 rows=296) (actual time=0.683..12833 rows=3.34e+6 loops=1)
-> Nested loop inner join (cost=315610 rows=296) (actual time=0.678..12159 rows=3.34e+6 loops=1)
-> Nested loop inner join (cost=314265 rows=2955) (actual time=0.626..4983 rows=3.34e+6 loops=1)
-> Nested loop inner join (cost=313663 rows=299) (actual time=0.323..2048 rows=334017 loops=1)
-> Filter: ((mgr.member_id = 3) and (mgr.ranking = 1) and (mgr.deleted_at is null)) (cost=310545 rows=2988) (actual time=0.26..1350 rows=334017 loops=1)
-> Table scan on mgr (cost=310545 rows=2.99e+6) (actual time=0.253..1098 rows=3e+6 loops=1)
-> Filter: (g.deleted_at is null) (cost=0.944 rows=0.1) (actual time=0.00179..0.0019 rows=1 loops=334017)
-> Single-row index lookup on g using PRIMARY (game_id=mgr.game_id) (cost=0.944 rows=1) (actual time=0.00164..0.00167 rows=1 loops=334017)
-> Covering index lookup on gq using idx_game_id_quiz_id (game_id=mgr.game_id) (cost=1.03 rows=9.89) (actual time=0.00292..0.00793 rows=10 loops=334017)
-> Filter: (q.deleted_at is null) (cost=0.355 rows=0.1) (actual time=0.00185..0.00196 rows=1 loops=3.34e+6)
-> Single-row index lookup on q using PRIMARY (quiz_id=gq.quiz_id) (cost=0.355 rows=1) (actual time=0.0017..0.00174 rows=1 loops=3.34e+6)
3. 마지막으로 서브쿼리를 한번 더 제거할 수 있을 것 같아서 아래와 같이 제거하였다.(똑같은 동작)
-- 개선 전
select category, COUNT(*)
from (select q.category, g.game_id
from game g
join game_quiz gq on g.game_id = gq.game_id
join quiz q on q.quiz_id = gq.quiz_id
where g.member_id = 1
group by q.category, g.game_id) AS bbb
group by bbb.category;
-- 개선 후
SELECT q.category, COUNT(DISTINCT g.game_id) AS game_count
FROM game g
JOIN game_quiz gq ON g.game_id = gq.game_id
JOIN quiz q ON q.quiz_id = gq.quiz_id
WHERE g.member_id = 1
GROUP BY q.category;기존에 조회 성능 약 12초에서 약 8초로 향상되었다.
중간 점검
이렇게 불필요한 쿼리문을 제거하고, 인덱스를 적용한 결과 기존 약 40초에서 약 8초까지는 줄일 수 있었다.
하지만 8초도 실제 서비스에서 사용하기에는 너무나도 느리다.
현재 지식에서는 마지막 쿼리에 대해 더이상 개선할 수 있는 부분이 보이지 않았고(그래서.. 튜닝 스터디도 시작..!)
다른 방법을 생각해보기로 했다.
혹시 기존에 테이블 설계에서 문제되었을 부분이 있었을까? 하는 생각으로 테이블을 다시 보게 되었다.
1. 서비스의 특성상 quiz 테이블의 카테고리 컬럼을 이용한 집계 조회가 자주 발생할 것이라고 예상된다.
2. 정규화나 반정규화를 고려해서 테이블을 수정해볼까?
우선 quiz는 category라는 필드를 가지고 있다.
하지만 game에서 사용된 quiz의 카테고리를 조회해오려면 복잡한(여러개의) join문이 사용되는데, 서비스의 다양한 조회로직에서 이러한 복잡한 join문이 반복 사용되고 있다.
그래서 연산을 통해 game테이블에서 category를 구할 수 있지만, 별도로 game테이블에도 category라는 필드를 추가해서 join연산을 하지 않도록 개선해 보고자 한다.
이렇게 하기 위해서는 categroy라는 별도의 테이블을 만들고, quiz와 game 테이블에서 참조하도록 하면 될 것 같다.
테이블수정 결과 전 -후 [그림]
이렇게 category 테이블을 추가하고 아래와 같은 쿼리로 수정하였고, 인덱스를 적용해보며 성능을 측정하였다.
-- 9. 특정 플레이어가 카테고리 별 승리한 횟수 조회
SELECT category_id, COUNT(*)
FROM game
WHERE member_id = 1
GROUP BY category_id;[측정 결과]
1. game 테이블 member_id에 인덱스 걸기, 500ms
2. game 테이블 category_id에 인덱스 걸기, 1s 100ms
3. game 테이블 멀티컬럼 인덱스 적용 (member_id, category_id), 110ms
4. game 테이블 멀티컬럼 인덱스 적용 (category_id, member_id), 230ms
최종적으로 (member_id, category_id)에 인덱스를 거는 방식으로 110ms까지 줄일 수 있었다.
(성능 + 자주 사용되는 필드와 조합 고려)
인덱스를 사용하는게 무조건 좋을까?
테이블과 쿼리를 개선해보고, 인덱스를 걸어주면서 성능을 개선해보았는데 인덱스를 걸어준다는 것은 내부에 정렬된 테이블을 만들어주는 것과 같다.(메모리를 더 사용)
실제로 인덱스를 걸지 않았을때와 걸었을 때의 메모리를 살펴보면 아래와 같다.
1. 인덱스 사용하지 않았을 경우
- Index_length: 테이블의 인덱스 크기
- Index_length: `0` (인덱스가 없으므로 메모리 공간을 사용하지 않음)
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
|Name|Engine|Version|Row_format|Rows |Avg_row_length|Data_length|Max_data_length|Index_length|Data_free|Auto_increment|Create_time |Update_time |Check_time|Collation |Checksum|Create_options|Comment|
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
|game|InnoDB|10 |Dynamic |995680|73 |72990720 |0 |0 |38797312 |1048561 |2024-09-12 08:08:48|2024-09-11 08:32:27|null |utf8mb4_0900_ai_ci|null | | |
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
2. 멀티 컬럼 인덱스 사용한 경우
- Index_length: `36,257,792` byte (멀티컬럼 인덱스가 추가되어 인덱스를 저장하기 위한 메모리 사용)
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
|Name|Engine|Version|Row_format|Rows |Avg_row_length|Data_length|Max_data_length|Index_length|Data_free|Auto_increment|Create_time |Update_time |Check_time|Collation |Checksum|Create_options|Comment|
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
|game|InnoDB|10 |Dynamic |995680|73 |72990720 |0 |36257792 |3145728 |1048561 |2024-09-12 08:01:09|2024-09-11 08:32:27|null |utf8mb4_0900_ai_ci|null | | |
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
결국 인덱스를 추가하면 메모리를 더 소모하지만, 조회 속도를 향상 시키는 장점이 있다.
데이터가 자주 변경될 경우 인덱스 테이블도 자주 업데이트 되어 오히려 성능에 부정적인 영향을 미칠 수 있다.
하지만 여기서 적용해본 '특정 플레이어가 카테고리별로 승리한 횟수'는 게임 결과를 누적하는 읽기전용 데이터로 사용되므로 인덱스를 걸어주는 방식으로 선택하게 되었다.
정규화와 반정규화?
기존 테이블을 수정하게 되었는데, 원래는 quiz테이블은 id -> question -> category 의 순서로 이행 종속성을 가지고 있었다.(quiestion에 따라 categroy가 결정되어버림)
그래서 3정규형을 위반하고 있었고 category라는 테이블로 분리하는 정규화 과정이 필요했었다.
category 테이블을 분리하고 보니 game테이블에 category_id를 추가해도 1, 2, 3 정규화는 위반하는 사항이 없었다. (만약 category 테이블을 분리하지 않았어도 성능을 위해 game 테이블 필드에 category를 추가해주는 반정규화를 선택 했을 것 같음)
그래서 최종적으로 테이블을 수정하는 방안을 선택하였다.
느낀 점
직접 SQL을 작성해보고 테이블 별로 약 100만개의 데이터를 삽입해서 측정/개선/분석 까지 해본 과정은 정말 좋았던 것 같다. 이론적으로 알고 있던 부분을 실습으로 해보니 정말 좋은 경험이었던 것 같다.
아쉬운 점은 복잡한 실행 계획을 해석하는데 어려움이 있었다.
또 쿼리를 효율적으로 개선하는 방법을 공부해야되겠다는 필요성을 느꼈다. (DISTINCT, JOIN전 필터링 등)
부족한 부분은 팀원과 함께 스터디를 해보면서 개선해보려고 한다.(SQL 튜닝 스터디)
알게된 점은 카디널리티가 높은 쪽으로 인덱스 설정을 고려해볼 것이었다. 직접 데이터를 넣고 실습해보니 이론와 더 와다았던 것 같다.
또, 테이블을 설계할 때 정규화를 체크해보고, 혹시 성능적으로 필요하다면 반정규화를 고려해봐도 되겠다는 것을 알게되었다. (읽기 특징을 가지는 데이터이고 복잡한 JOIN문을 사용하는 경우)
실제로 이번 프로젝트에 정규화/반정규화 과정을 통해서 대부분의 조회쿼리(프로젝트에 사용하는 나머지 여러개의 쿼리에 대해서도 향상이 있었음)에서 이득이 있었다.
물론 반정규화의 경우네는 이상현상 발생 가능성을 인지하고 있어야 할 것같다.
'프로젝트 > CStar' 카테고리의 다른 글
| [프로젝트] 패키지 구조에대한 고민 (0) | 2024.09.09 |
|---|---|
| [프로젝트] 게임 엔진 ThreadPool Size는 어떻게 설정해야 할까? [작성중] (1) | 2024.09.08 |
| [프로젝트] Redis 아키텍처 적용해보기(feat. sentinel) [작성중] (0) | 2024.09.07 |
| [프로젝트] Redis 를 Queue로 활용했을때 성능 & 동시성 체크해보자 (0) | 2024.09.04 |
| [프로젝트] Busy Waiting 어떻게 개선해볼 수 있을까? (0) | 2024.09.02 |
테이블 더미데이터 삽입(약 100만개)
프로젝트에 적용시켜 볼 조회쿼리에 대한 성능을 측정하기로 했다.
성능 측정에 필요한 테이블에 약 100만개 정도의 데이터를 삽입하기로 했다.
프로젝트에서 사용한 테이블 구조는 아래와 같다.
복잡한 조회에 사용되는 테이블은 크게 아래 4개와 같다.
game, member_game_result, game_quiz, quiz
그래서 4개의 테이블에 약 100만개의 데이터를 삽입해주었다.
아래와 같은 코드를 통해 정합성을 맞춰주면서 랜덤 데이터를 최대한 넣어 주었습니다!
퀴즈 테이블(quiz) -> 100만개 생성
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- 더미 데이터 삽입 쿼리
INSERT INTO quiz (member_id, question, answer, category, created_at, updated_at, deleted_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR(1 + RAND() * 3) AS member_id,
CONCAT('문제 ', LPAD(n, 7, '0')) AS question,
CONCAT('정답 ', LPAD(n, 7, '0')) AS answer,
ELT(FLOOR(1 + RAND() * 5), 'NETWORK', 'ALGORITHM', 'OPERATING_SYSTEM', 'DATABASE', 'DESIGN_PATTERN') AS category,
NOW() - INTERVAL (n) MINUTE AS created_at,
NOW() - INTERVAL (n) MINUTE AS updated_at,
NULL AS deleted_at
FROM cte;
게임 테이블(game) -> 100만개 생성
-- 더미 데이터 삽입 쿼리
INSERT INTO game (room_id, member_id, total_quiz_count, started_at, created_at, updated_at, deleted_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR(1 + RAND() * 10) AS room_id,
FLOOR(1 + RAND() * 3) AS member_id,
10 AS total_quiz_count,
NOW() - INTERVAL (n + 1) MINUTE AS started_at,
NOW() - INTERVAL (n) MINUTE AS created_at,
NOW() - INTERVAL (n) MINUTE AS updated_at,
NULL AS deleted_at
FROM cte;
-- 컬럼별 더미 데이터 삽입
-- 1. room_id : 게임방 10개 랜덤으로 삽입
-- 2. member_id : 멤버 3명 랜덤으로 삽입
-- 3. total_quiz_count : 10개
-- 4. started_at : 게임 시작 시간은 created_at(게임 종료 시간) 보다 빨라야 한다
-- 5. created_at, updated_at는 현재 시간 기준 n분 전으로 설정
-- 6. deleted_at는 전부 null로 설정해 삭제된 데이터 없음
게임-퀴즈 테이블(game_quiz) -> 1000만개(게임에서 활용된 퀴즈 개수가 10개라고 가정하였습니다.)
// [임시 테이블 생성]
// 게임_퀴즈 테이블의 경우 정합성을 맞춰야 하는 문제가 있음
// 한 게임 아이디에 해당하는 퀴즈들의 카테고리는 일치해야함
// 따라서 임시 테이블마다 카테고리 하나씩 담당해서 랜덤으로 삽입 후
// id 기본키를 삽입해 시간복잡도 O(1)으로 만들어서 접근하게 함
CREATE TABLE tmp_network (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
CREATE TABLE tmp_algorithm (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
CREATE TABLE tmp_operating_system (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
CREATE TABLE tmp_database (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
CREATE TABLE tmp_design_pattern (
id BIGINT NOT NULL auto_increment PRIMARY KEY,
quiz_id BIGINT NOT NULL
);
-- 임시 테이블
INSERT INTO tmp_network (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'NETWORK';
INSERT INTO tmp_algorithm (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'ALGORITHM';
INSERT INTO tmp_operating_system (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'OPERATING_SYSTEM';
INSERT INTO tmp_database (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'DATABASE';
INSERT INTO tmp_design_pattern (quiz_id)
SELECT quiz_id
FROM quiz
WHERE quiz.category = 'DESIGN_PATTERN';
------------------------------------------------------------------------------------------
// 테이블 삽입
-- 쿼리 콘솔마다 세션 적용되므로 각각 적용 시켜줘야함
SET SESSION cte_max_recursion_depth = 10000000;
-- 더미 데이터 삽입 쿼리
INSERT INTO game_quiz (game_id, quiz_id)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 10000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR((n - 1) / 10) + 1 AS game_id,
CASE FLOOR((((n - 1) / 10) + 1) % 5 + 1)
WHEN 1 THEN (SELECT quiz_id
FROM tmp_algorithm
WHERE id = (n % 190000) + 1
)
WHEN 2 THEN (SELECT quiz_id
FROM tmp_network
WHERE id = (n % 190000) + 1
)
WHEN 3 THEN (SELECT quiz_id
FROM tmp_database
WHERE id = (n % 190000) + 1
)
WHEN 4 THEN (SELECT quiz_id
FROM tmp_design_pattern
WHERE id = (n % 190000) + 1
)
WHEN 5 THEN (SELECT quiz_id
FROM tmp_operating_system
WHERE id = (n % 190000) + 1
)
ELSE 9999
END AS quiz_id
FROM cte;
멤버-게임-결과 테이블(member_game_result) -> 300만개
-- 더미 데이터 삽입 쿼리
INSERT INTO member_game_result (game_id, member_id, total_count, correct_count, ranking,
created_at, updated_at, deleted_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 3000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
FLOOR((n - 1) / 3) + 1 AS game_id,
FLOOR((n - 1) % 3) + 1 AS member_id,
10 AS total_count,
(CASE (SELECT member_id
FROM game
WHERE game_id = FLOOR((n - 1) / 3) + 1)
WHEN FLOOR((n - 1) % 3) + 1 THEN 5
ELSE 2
END
) AS correct_count,
(CASE (SELECT member_id
FROM game
WHERE game_id = FLOOR((n - 1) / 3) + 1)
WHEN FLOOR((n - 1) % 3) + 1 THEN 1
ELSE 2
END
) AS ranking,
NOW() - INTERVAL (n) MINUTE AS created_at,
NOW() - INTERVAL (n) MINUTE AS updated_at,
NULL AS deleted_at
FROM cte;
-- 컬럼별 더미 데이터 삽입
-- 1. game_id : 3개의 n 값마다 game_id가 1씩 증가 (1,1,1,2,2,2,3,3,3 ...)
-- 2. member_id : 3의 주기로 1, 2, 3을 반복 (1,2,3,1,2,3 ...)
-- 3. total_count : 10개
-- 4. correct_count : 승리자의 경우 맞춘 개수 5개, 나머지 두 멤버는 2개씩 삽입
-- 5. ranking : 승리자의 경우 랭킹 1위, 나머지 두 멤버는 2위로 삽입
-- 6. created_at, updated_at는 현재 시간 기준 n분 전으로 설정
-- 7. deleted_at는 전부 null로 설정해 삭제된 데이터 없음
생각보다 정합성을 맞춰주면서 많은 랜덤 데이터를 넣어주는 코드를 작성하는 것이 쉽지 않았다.
더 좋은 방법이 있었을 수도 있지만, 우선 생각나는 대로 작성해 보았고, 무사히(?) 생성할 수 있었다.
그럼이제 성능 측정 가보자고~
조회 성능 측정해보기
9번. 특정 플레이어가 카테고리별 승리한 횟수를 조회하는 쿼리를 개선해보기로 했다.
(조회 특징을 가지는 쿼리는 page형태로 LIMIT을 걸어서 가져올 수 있는 부분이었다. 그 중에서 '특정 플레이어의 카테고리별 승리 횟수 조회'는 비즈니스 적으로도 가장 궁금해 할 수 있기 때문에 성능 개선후 플젝에 빠르게 적용시켜보고자 선택하였다)
대체 저 40초 로직은 어떻게 쿼리를 작성했길래 저 모양이야..?
네... 바로 아래와 같습니다
SELECT
mgr.member_id,
q.category,
COUNT(DISTINCT g.game_id) AS win_count_by_category
FROM
quiz AS q
INNER JOIN game_quiz AS gq ON q.quiz_id = gq.quiz_id
INNER JOIN game AS g ON gq.game_id = g.game_id
INNER JOIN member_game_result AS mgr ON g.game_id = mgr.game_id
WHERE
mgr.ranking = 1
AND mgr.member_id = '3'
AND q.deleted_at IS NULL
AND g.deleted_at IS NULL
AND mgr.deleted_at IS NULL
GROUP BY
mgr.member_id,
q.category;
-- [2024-09-10 00:09:51] 40 s 895 ms (execution: 40 s 866 ms, fetching: 29 ms)에서 1부터 5개 행을 불러왔습니다
EXPLAIN : 우선 위의 쿼리에 대해 실행 계획을 살펴보면 아래와 같다.
+--+-----------+-----+----------+------+-------------+-------+-------+-------------------+-------+--------+------------------------------------------+
|id|select_type|table|partitions|type |possible_keys|key |key_len|ref |rows |filtered|Extra |
+--+-----------+-----+----------+------+-------------+-------+-------+-------------------+-------+--------+------------------------------------------+
|1 |SIMPLE |gq |null |ALL |null |null |null |null |9741573|100 |Using temporary; Using filesort |
|1 |SIMPLE |q |null |eq_ref|PRIMARY |PRIMARY|8 |cstar_db.gq.quiz_id|1 |10 |Using where |
|1 |SIMPLE |g |null |eq_ref|PRIMARY |PRIMARY|8 |cstar_db.gq.game_id|1 |10 |Using where |
|1 |SIMPLE |mgr |null |ALL |null |null |null |null |2987614|0.01 |Using where; Using join buffer (hash join)|
+--+-----------+-----+----------+------+-------------+-------+-------+-------------------+-------+--------+------------------------------------------+full table scan이 2개나 존재하고 실제로 rows를 보면 행을 굉장히 많이탐색했다는 것을 알 수 있다.
EXPLAIN ANALYYZE : 조금 더 자세히 알아보면 아래와 같다.
-> Group aggregate: count(distinct game.game_id) (actual time=52382..53275 rows=5 loops=1)
-> Sort: q.category (actual time=52173..52396 rows=3.33e+6 loops=1)
-> Stream results (cost=139e+6 rows=2910) (actual time=46656..50792 rows=3.33e+6 loops=1)
-> Inner hash join (mgr.game_id = gq.game_id) (cost=139e+6 rows=2910) (actual time=46656..50203 rows=3.33e+6 loops=1)
-> Filter: ((mgr.member_id = 3) and (mgr.ranking = 1) and (mgr.deleted_at is null)) (cost=1266 rows=299) (actual time=0.31..1230 rows=332942 loops=1)
-> Table scan on mgr (cost=1266 rows=2.99e+6) (actual time=0.295..1009 rows=3e+6 loops=1)
-> Hash
-> Nested loop inner join (cost=12.8e+6 rows=97416) (actual time=0.562..44434 rows=10e+6 loops=1)
-> Nested loop inner join (cost=11.7e+6 rows=974157) (actual time=0.193..37848 rows=10e+6 loops=1)
-> Table scan on gq (cost=999175 rows=9.74e+6) (actual time=0.121..5100 rows=10e+6 loops=1)
-> Filter: (q.deleted_at is null) (cost=1 rows=0.1) (actual time=0.00298..0.00308 rows=1 loops=10e+6)
-> Single-row index lookup on q using PRIMARY (quiz_id=gq.quiz_id) (cost=1 rows=1) (actual time=0.00283..0.00287 rows=1 loops=10e+6)
-> Filter: (g.deleted_at is null) (cost=1 rows=0.1) (actual time=365e-6..470e-6 rows=1 loops=10e+6)
-> Single-row index lookup on g using PRIMARY (game_id=gq.game_id) (cost=1 rows=1) (actual time=218e-6..253e-6 rows=1 loops=10e+6)
사실 이때부터 분석이 점점 어려워지고 분석하는 방법에 대해 자세히 공부해봐야 겠다는 생각을 하게되었다.
(명령어만 칠줄 아는 바보..) -> SQL 쿼리 튜닝 스터디를 시작하게 된 계기..(링크 걸 예정)
우선 개선시도를 아래와 같은 단계로 해보았다.
1. 비효율적인 쿼리 개선
2. 인덱스등을 활용한 개선
3. 테이블 수정하기
1. 기존에 쿼리에서 혹시 굳이 사용하지 않아도 되는구문이 있는지, 불필요하게 사용된 구문이 있는지 확인하고 제거해주었다.
-- 기존쿼리 : 특정 플레이어가 카테고리 별 승리한 횟수 조회 (약 40초)
SELECT
mgr.member_id,
q.category,
COUNT(DISTINCT g.game_id) AS win_count_by_category
FROM
quiz AS q
INNER JOIN game_quiz AS gq ON q.quiz_id = gq.quiz_id
INNER JOIN game AS g ON gq.game_id = g.game_id
INNER JOIN member_game_result AS mgr ON g.game_id = mgr.game_id
WHERE
mgr.ranking = 1
AND mgr.member_id = '3'
GROUP BY
q.category;
-- 개선 쿼리 :
select category, COUNT(*)
from (select q.category, g.game_id
from game g
join game_quiz gq on g.game_id = gq.game_id
join quiz q on q.quiz_id = gq.quiz_id
where g.member_id = 1
group by q.category, g.game_id) AS bbb
group by bbb.category;game 테이블의 member_id는 승리자의 아이디이고, 해당 값은 주어질 이미 주어질 예정이기 때문에 mgr.ranking = 1을 가져올 필요가 없다. 그래서 조인 대상에서 삭제해 주었다.
성능 적인 부분에서는 큰 변화 없없음
2. 인덱스를 적용해보자.
game_quiz라는 맵핑 형태의 테이블을 통해 game과 quiz를 조회 하고있다.실제로 인덱스가 적용되지 않은 채로 join연산을 하는것을 앞의 실행계획에서 확인했었다.
인덱스를 걸어주고난 결과는 아래와 같다.
game_quiz의 game_id필드에 인덱스를 설정한 경우 -> 약 21초
// 게임 아이디에 하나 인덱스
- 카디널리티가 퀴즈 아이디 하나 인덱스 걸었을 때보다 높다
- 게임 아이디는 10개만 중복, 퀴즈 아이디는 중복이 훨씬 많다.
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|Table |Non_unique|Key_name |Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|Visible|Expression|
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|game_quiz|1 |idx_game_id|1 |game_id |A |998215 |null |null | |BTREE | | |YES |null |
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
game_quiz의 quiz_id필드에 인덱스를 설정한 경우 -> 약 1분 18초
// 퀴즈 아이디에 하나 인덱스
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|Table |Non_unique|Key_name |Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|Visible|Expression|
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|game_quiz|1 |idx_quiz_id|1 |quiz_id |A |190879 |null |null | |BTREE | | |YES |null |
+---------+----------+-----------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
game_id는 약 20초로 성능향상이 있었고, quiz_id는 약 1분 18초로 성능이 느려졌다.
인덱스를 걸었을 때 카디널리티가 game_id에 걸었을 때가 더 높기 때문이라고 생각한다.
(quiz는 카테고리 별로 약 20만개씩 5덩어리가 존재하고, 그 중에서 랜덤으로 game_id에 10개씩 매칭되는데, 그래서 카디널리티가 더 낮다고 생각됨)
마지막으로 멀티컬럼 인덱스를 적용해보았는데, game_id의 카디널리티가 더 높으므로 (game_id, quiz_id)로 걸었을 때 더 좋은 성능이 나왔다. -> 약 12초
[실행계획 확인]
// 멀티 컬럼 인덱스 -> game id 부터
CREATE INDEX idx_game_id_quiz_id ON game_quiz (game_id, quiz_id);
+---------+----------+-------------------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|Table |Non_unique|Key_name |Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|Visible|Expression|
+---------+----------+-------------------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
|game_quiz|1 |idx_game_id_quiz_id|1 |game_id |A |983100 |null |null | |BTREE | | |YES |null |
|game_quiz|1 |idx_game_id_quiz_id|2 |quiz_id |A |9724594 |null |null | |BTREE | | |YES |null |
+---------+----------+-------------------+------------+-----------+---------+-----------+--------+------+----+----------+-------+-------------+-------+----------+
// EXPLAIN
+--+-----------+-----+----------+------+-------------------+-------------------+-------+--------------------+-------+--------+--------------------------------------------+
|id|select_type|table|partitions|type |possible_keys |key |key_len|ref |rows |filtered|Extra |
+--+-----------+-----+----------+------+-------------------+-------------------+-------+--------------------+-------+--------+--------------------------------------------+
|1 |SIMPLE |mgr |null |ALL |null |null |null |null |2987614|0.1 |Using where; Using temporary; Using filesort|
|1 |SIMPLE |g |null |eq_ref|PRIMARY |PRIMARY |8 |cstar_db.mgr.game_id|1 |10 |Using where |
|1 |SIMPLE |gq |null |ref |idx_game_id_quiz_id|idx_game_id_quiz_id|8 |cstar_db.mgr.game_id|9 |100 |Using index |
|1 |SIMPLE |q |null |eq_ref|PRIMARY |PRIMARY |8 |cstar_db.gq.quiz_id |1 |10 |Using where |
+--+-----------+-----+----------+------+-------------------+-------------------+-------+--------------------+-------+--------+--------------------------------------------+
// EXPLAIN ANALYZE
-> Group aggregate: count(distinct game.game_id) (actual time=14600..15507 rows=5 loops=1)
-> Sort: q.category (actual time=14384..14620 rows=3.34e+6 loops=1)
-> Stream results (cost=315610 rows=296) (actual time=0.683..12833 rows=3.34e+6 loops=1)
-> Nested loop inner join (cost=315610 rows=296) (actual time=0.678..12159 rows=3.34e+6 loops=1)
-> Nested loop inner join (cost=314265 rows=2955) (actual time=0.626..4983 rows=3.34e+6 loops=1)
-> Nested loop inner join (cost=313663 rows=299) (actual time=0.323..2048 rows=334017 loops=1)
-> Filter: ((mgr.member_id = 3) and (mgr.ranking = 1) and (mgr.deleted_at is null)) (cost=310545 rows=2988) (actual time=0.26..1350 rows=334017 loops=1)
-> Table scan on mgr (cost=310545 rows=2.99e+6) (actual time=0.253..1098 rows=3e+6 loops=1)
-> Filter: (g.deleted_at is null) (cost=0.944 rows=0.1) (actual time=0.00179..0.0019 rows=1 loops=334017)
-> Single-row index lookup on g using PRIMARY (game_id=mgr.game_id) (cost=0.944 rows=1) (actual time=0.00164..0.00167 rows=1 loops=334017)
-> Covering index lookup on gq using idx_game_id_quiz_id (game_id=mgr.game_id) (cost=1.03 rows=9.89) (actual time=0.00292..0.00793 rows=10 loops=334017)
-> Filter: (q.deleted_at is null) (cost=0.355 rows=0.1) (actual time=0.00185..0.00196 rows=1 loops=3.34e+6)
-> Single-row index lookup on q using PRIMARY (quiz_id=gq.quiz_id) (cost=0.355 rows=1) (actual time=0.0017..0.00174 rows=1 loops=3.34e+6)
3. 마지막으로 서브쿼리를 한번 더 제거할 수 있을 것 같아서 아래와 같이 제거하였다.(똑같은 동작)
-- 개선 전
select category, COUNT(*)
from (select q.category, g.game_id
from game g
join game_quiz gq on g.game_id = gq.game_id
join quiz q on q.quiz_id = gq.quiz_id
where g.member_id = 1
group by q.category, g.game_id) AS bbb
group by bbb.category;
-- 개선 후
SELECT q.category, COUNT(DISTINCT g.game_id) AS game_count
FROM game g
JOIN game_quiz gq ON g.game_id = gq.game_id
JOIN quiz q ON q.quiz_id = gq.quiz_id
WHERE g.member_id = 1
GROUP BY q.category;기존에 조회 성능 약 12초에서 약 8초로 향상되었다.
중간 점검
이렇게 불필요한 쿼리문을 제거하고, 인덱스를 적용한 결과 기존 약 40초에서 약 8초까지는 줄일 수 있었다.
하지만 8초도 실제 서비스에서 사용하기에는 너무나도 느리다.
현재 지식에서는 마지막 쿼리에 대해 더이상 개선할 수 있는 부분이 보이지 않았고(그래서.. 튜닝 스터디도 시작..!)
다른 방법을 생각해보기로 했다.
혹시 기존에 테이블 설계에서 문제되었을 부분이 있었을까? 하는 생각으로 테이블을 다시 보게 되었다.
1. 서비스의 특성상 quiz 테이블의 카테고리 컬럼을 이용한 집계 조회가 자주 발생할 것이라고 예상된다.
2. 정규화나 반정규화를 고려해서 테이블을 수정해볼까?
우선 quiz는 category라는 필드를 가지고 있다.
하지만 game에서 사용된 quiz의 카테고리를 조회해오려면 복잡한(여러개의) join문이 사용되는데, 서비스의 다양한 조회로직에서 이러한 복잡한 join문이 반복 사용되고 있다.
그래서 연산을 통해 game테이블에서 category를 구할 수 있지만, 별도로 game테이블에도 category라는 필드를 추가해서 join연산을 하지 않도록 개선해 보고자 한다.
이렇게 하기 위해서는 categroy라는 별도의 테이블을 만들고, quiz와 game 테이블에서 참조하도록 하면 될 것 같다.
테이블수정 결과 전 -후 [그림]
이렇게 category 테이블을 추가하고 아래와 같은 쿼리로 수정하였고, 인덱스를 적용해보며 성능을 측정하였다.
-- 9. 특정 플레이어가 카테고리 별 승리한 횟수 조회
SELECT category_id, COUNT(*)
FROM game
WHERE member_id = 1
GROUP BY category_id;[측정 결과]
1. game 테이블 member_id에 인덱스 걸기, 500ms
2. game 테이블 category_id에 인덱스 걸기, 1s 100ms
3. game 테이블 멀티컬럼 인덱스 적용 (member_id, category_id), 110ms
4. game 테이블 멀티컬럼 인덱스 적용 (category_id, member_id), 230ms
최종적으로 (member_id, category_id)에 인덱스를 거는 방식으로 110ms까지 줄일 수 있었다.
(성능 + 자주 사용되는 필드와 조합 고려)
인덱스를 사용하는게 무조건 좋을까?
테이블과 쿼리를 개선해보고, 인덱스를 걸어주면서 성능을 개선해보았는데 인덱스를 걸어준다는 것은 내부에 정렬된 테이블을 만들어주는 것과 같다.(메모리를 더 사용)
실제로 인덱스를 걸지 않았을때와 걸었을 때의 메모리를 살펴보면 아래와 같다.
1. 인덱스 사용하지 않았을 경우
- Index_length: 테이블의 인덱스 크기
- Index_length: `0` (인덱스가 없으므로 메모리 공간을 사용하지 않음)
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
|Name|Engine|Version|Row_format|Rows |Avg_row_length|Data_length|Max_data_length|Index_length|Data_free|Auto_increment|Create_time |Update_time |Check_time|Collation |Checksum|Create_options|Comment|
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
|game|InnoDB|10 |Dynamic |995680|73 |72990720 |0 |0 |38797312 |1048561 |2024-09-12 08:08:48|2024-09-11 08:32:27|null |utf8mb4_0900_ai_ci|null | | |
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
2. 멀티 컬럼 인덱스 사용한 경우
- Index_length: `36,257,792` byte (멀티컬럼 인덱스가 추가되어 인덱스를 저장하기 위한 메모리 사용)
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
|Name|Engine|Version|Row_format|Rows |Avg_row_length|Data_length|Max_data_length|Index_length|Data_free|Auto_increment|Create_time |Update_time |Check_time|Collation |Checksum|Create_options|Comment|
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
|game|InnoDB|10 |Dynamic |995680|73 |72990720 |0 |36257792 |3145728 |1048561 |2024-09-12 08:01:09|2024-09-11 08:32:27|null |utf8mb4_0900_ai_ci|null | | |
+----+------+-------+----------+------+--------------+-----------+---------------+------------+---------+--------------+-------------------+-------------------+----------+------------------+--------+--------------+-------+
결국 인덱스를 추가하면 메모리를 더 소모하지만, 조회 속도를 향상 시키는 장점이 있다.
데이터가 자주 변경될 경우 인덱스 테이블도 자주 업데이트 되어 오히려 성능에 부정적인 영향을 미칠 수 있다.
하지만 여기서 적용해본 '특정 플레이어가 카테고리별로 승리한 횟수'는 게임 결과를 누적하는 읽기전용 데이터로 사용되므로 인덱스를 걸어주는 방식으로 선택하게 되었다.
정규화와 반정규화?
기존 테이블을 수정하게 되었는데, 원래는 quiz테이블은 id -> question -> category 의 순서로 이행 종속성을 가지고 있었다.(quiestion에 따라 categroy가 결정되어버림)
그래서 3정규형을 위반하고 있었고 category라는 테이블로 분리하는 정규화 과정이 필요했었다.
category 테이블을 분리하고 보니 game테이블에 category_id를 추가해도 1, 2, 3 정규화는 위반하는 사항이 없었다. (만약 category 테이블을 분리하지 않았어도 성능을 위해 game 테이블 필드에 category를 추가해주는 반정규화를 선택 했을 것 같음)
그래서 최종적으로 테이블을 수정하는 방안을 선택하였다.
느낀 점
직접 SQL을 작성해보고 테이블 별로 약 100만개의 데이터를 삽입해서 측정/개선/분석 까지 해본 과정은 정말 좋았던 것 같다. 이론적으로 알고 있던 부분을 실습으로 해보니 정말 좋은 경험이었던 것 같다.
아쉬운 점은 복잡한 실행 계획을 해석하는데 어려움이 있었다.
또 쿼리를 효율적으로 개선하는 방법을 공부해야되겠다는 필요성을 느꼈다. (DISTINCT, JOIN전 필터링 등)
부족한 부분은 팀원과 함께 스터디를 해보면서 개선해보려고 한다.(SQL 튜닝 스터디)
알게된 점은 카디널리티가 높은 쪽으로 인덱스 설정을 고려해볼 것이었다. 직접 데이터를 넣고 실습해보니 이론와 더 와다았던 것 같다.
또, 테이블을 설계할 때 정규화를 체크해보고, 혹시 성능적으로 필요하다면 반정규화를 고려해봐도 되겠다는 것을 알게되었다. (읽기 특징을 가지는 데이터이고 복잡한 JOIN문을 사용하는 경우)
실제로 이번 프로젝트에 정규화/반정규화 과정을 통해서 대부분의 조회쿼리(프로젝트에 사용하는 나머지 여러개의 쿼리에 대해서도 향상이 있었음)에서 이득이 있었다.
물론 반정규화의 경우네는 이상현상 발생 가능성을 인지하고 있어야 할 것같다.
'프로젝트 > CStar' 카테고리의 다른 글
| [프로젝트] 패키지 구조에대한 고민 (0) | 2024.09.09 |
|---|---|
| [프로젝트] 게임 엔진 ThreadPool Size는 어떻게 설정해야 할까? [작성중] (1) | 2024.09.08 |
| [프로젝트] Redis 아키텍처 적용해보기(feat. sentinel) [작성중] (0) | 2024.09.07 |
| [프로젝트] Redis 를 Queue로 활용했을때 성능 & 동시성 체크해보자 (0) | 2024.09.04 |
| [프로젝트] Busy Waiting 어떻게 개선해볼 수 있을까? (0) | 2024.09.02 |